![]()
![]()

![]()
Bringing Powerful ‘SAS’ Inspired Concepts for more Efficient Bigger Outputs to ‘R’.
The main goal is to make descriptive evaluations easier to create bigger and more complex outputs in less time with less code. Introducing format containers with multilabels, a more powerful summarise which is capable to output every possible combination of the provided grouping variables in one go, tabulation functions which can create any table in different styles and other more readable functions. The code is optimized to work fast even with datasets of over a million observations.
# Official release
install.packages("qol")
# Development version
devtools::install_github("s3rdia/qol")
install.packages('qol', repos = c('https://s3rdia.r-universe.dev', 'https://cloud.r-project.org'))
pak::pak("s3rdia/qol")Create a format container independent from any data frame. Define which values should be recoded into which new categories, if the format is applied to a variable in a data frame. It is possible to assign a single value to multiple new categories to create a multilabel. With these format containers, you just keep a small reference of original values and result categories. Formats and data find their way together only just before computing the results. This method is very memory efficient, readable and user friendly for creating larger and more complex outputs at the same time.
# Creating format containers
age. <- discrete_format(
"Total" = 0:100,
"under 18" = 0:17,
"18 to under 25" = 18:24,
"25 to under 55" = 25:54,
"55 to under 65" = 55:64,
"65 and older" = 65:100)
sex. <- discrete_format(
"Total" = 1:2,
"Male" = 1,
"Female" = 2)The package builds on the incredibly fast collapse and data.table packages. In addition the code is optimized to handle big datasets efficiently with the format concept.
library(qol)
# If you want to test the raw speed in combination with creating big outputs try this:
# Lets crank up the observations to 10 Millions
my_data <- dummy_data(10000000)
# Create format containers
age. <- discrete_format(
"Total" = 0:100,
"under 18" = 0:17,
"18 to under 25" = 18:24,
"25 to under 55" = 25:54,
"55 to under 65" = 55:64,
"65 and older" = 65:100)
sex. <- discrete_format(
"Total" = 1:2,
"Male" = 1,
"Female" = 2)
education. <- discrete_format(
"Total" = c("low", "middle", "high"),
"low education" = "low",
"middle education" = "middle",
"high education" = "high")
# And now let's take a second and see what massive outputs we can get in no time
summary_df <- my_data |>
summarise_plus(class = c(year, sex, age, education),
values = c(income, probability, weight),
statistics = c("freq", "sum", "sum_wgt", "pct_group", "pct_total", "missing"),
formats = list(age = age.,
sex = sex.,
education = education.),
weight = "weight",
nesting = "all",
notes = FALSE)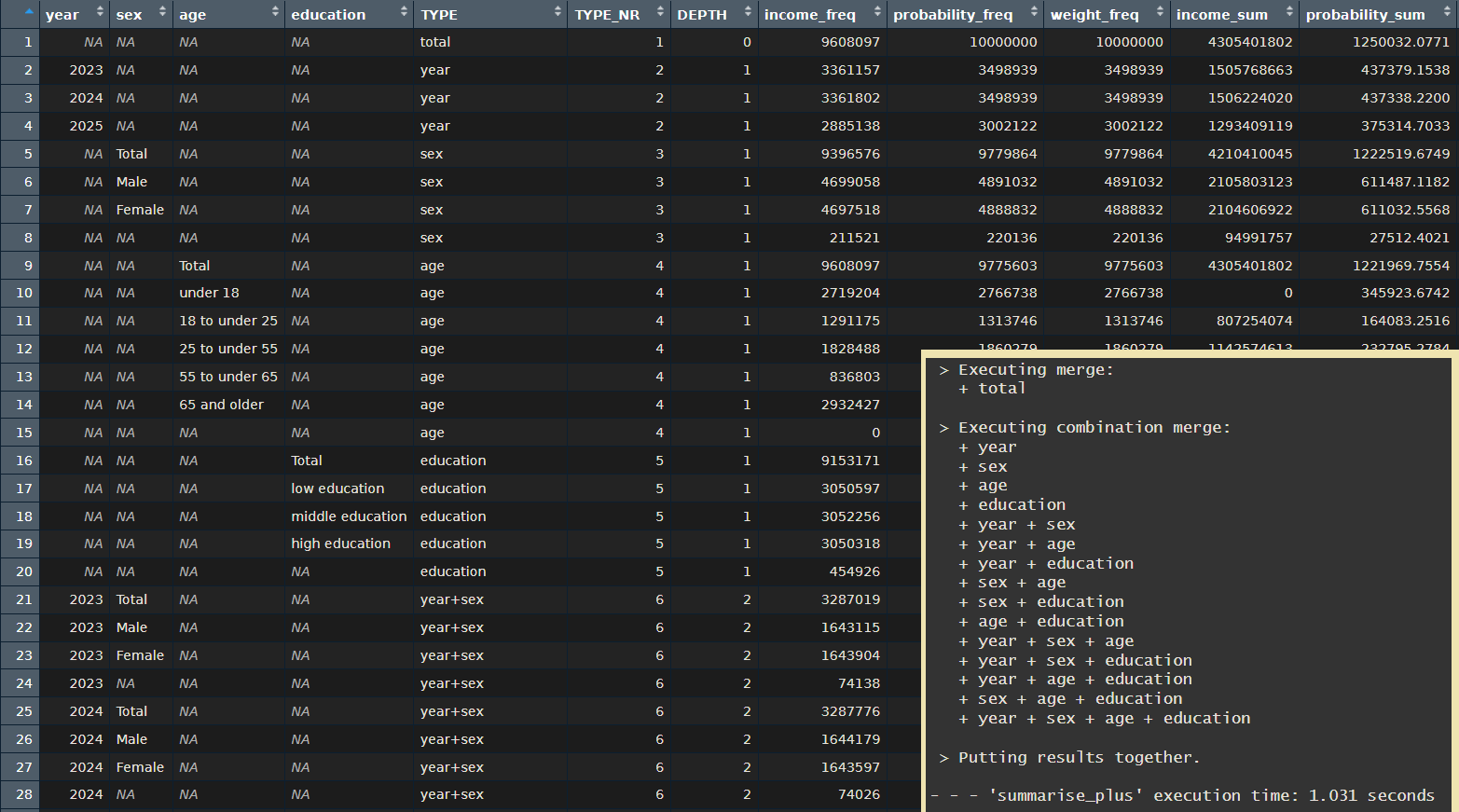
The operations based on summarisation are the fastest. Other operations take a bit longer but still work fast with big datasets.
Using the wonderful openxlsx2 package for maximum style, you can basically output any table fully styled with little effort. Combine any number of variables in any possible way, all at once. Setting up a custom, reusable style is as easy as setting up options like: provide a color for the table header, set the font size for the row header, should borders be drawn for the table cells yes/no, and so on. You can fully concentrate on designing a table, instead of thinking hard about how to calculate where to put a border or to even manually prepare a designed workbook.
my_data <- dummy_data(100000)
# Create format containers
age. <- discrete_format(
"Total" = 0:100,
"under 18" = 0:17,
"18 to under 25" = 18:24,
"25 to under 55" = 25:54,
"55 to under 65" = 55:64,
"65 and older" = 65:100)
sex. <- discrete_format(
"Total" = 1:2,
"Male" = 1,
"Female" = 2)
education. <- discrete_format(
"Total" = c("low", "middle", "high"),
"low education" = "low",
"middle education" = "middle",
"high education" = "high")
# Define style
set_style_options(column_widths = c(2, 15, 15, 15, 9))
# Define titles and footnotes. If you want to add hyperlinks you can do so by
# adding "link:" followed by the hyperlink to the main text.
set_titles("This is title number 1 link: https://cran.r-project.org/",
"This is title number 2",
"This is title number 3")
set_footnotes("This is footnote number 1",
"This is footnote number 2",
"This is footnote number 3 link: https://cran.r-project.org/")
# Output complex tables with different percentages
my_data |> any_table(rows = c("sex + age", "sex", "age"),
columns = c("year", "education + year"),
values = weight,
statistics = c("sum", "pct_group"),
pct_group = c("sex", "age"),
formats = list(sex = sex., age = age.,
education = education.),
na.rm = TRUE)
reset_style_options()
reset_qol_options()
You can also combine multiple tables in one workbook, each on a different sheet, and save the file, instead of just viewing it.
# Set output and style options globally
set_style_options(save_path = "C:/My_folder/",
file = "My_workbook.xlsx",
sheet_name = "age_sex")
# Capture the output of any_table() to get a list which contains the data frame
# as well as the formatted workbook.
# Note: Set print to FALSE to prevent the workbook from being saved to early.
result_list <- my_data |>
any_table(rows = c("age"),
columns = c("sex"),
values = weight,
statistics = c("sum"),
formats = list(sex = sex., age = age.),
na.rm = TRUE,
print = FALSE)
# Set a new sheet name for the next table
set_style_options(sheet_name = "edu_year")
# Pass on the workbook from before to the next any_table()
# print is now TRUE so the workbook will be saved.
my_data |> any_table(workbook = result_list[["workbook"]],
rows = c("education"),
columns = c("year"),
values = weight,
statistics = c("pct_group"),
formats = list(education = education.),
na.rm = TRUE)
# For safety set file back to NULL at the end. Otherwise the next any_table() will overwrite
# the existing file.
close_file()In case you have a good amount of tables, you want to combine in a single workbook, you can also catch the outputs and combine them afterwards in one go:
# Set output and style options globally
set_style_options(sheet_name = "age_sex")
# Catch the output as shown before, but additionally use the option -> output = "excel_nostyle".
# This skips the styling part, so that the function runs faster. The styling is done later on.
tab1 <- my_data |>
any_table(rows = c("age"),
columns = c("sex"),
values = weight,
statistics = c("sum"),
formats = list(sex = sex., age = age.),
na.rm = TRUE,
print = FALSE,
output = "excel_nostyle")
# Now let's asume you create a bunch of different tables
set_style_options(sheet_name = "sheet2")
tab2 <- my_data |> any_table(..., print = FALSE, output = "excel_nostyle")
set_style_options(sheet_name = "sheet3")
tab3 <- my_data |> any_table(..., print = FALSE, output = "excel_nostyle")
set_style_options(sheet_name = "sheet4")
tab4 <- my_data |> any_table(..., print = FALSE, output = "excel_nostyle")
...
# Every of the above tabs is a list, which contains the data table, an unstyled workbook and the meta
# information needed for the individual styling. These tabs can be input into the following function,
# which reads the meta information, styles each table individually and combines them as separate sheets
# into a single workbook.
combine_into_workbook(tab1, tab2, tab3, tab4, tab5, tab6, tab7, tab8,
file = "C:/My_folder/My_workbook.xlsx")The package offers file saving in the standard rds format or the
incredibly fast fst
format. By default the saving function write protects any existing
files. So nothing gets overwritten unless you say so.
The loading functions are able to keep only the desired variables, but
with a twist: You can write the variable names as you like. They are
always found, whether you use small letters or big ones or something in
between. And they are retrieved in provided order.
# Save file
my_data |> save_file(path = tempdir(),
file = "testfile.fst",
keep = c(income_class, sex, age, state, weight, NUTS3),
where = sex == 1)
# Load file
my_fst_where <- load_file(path = tempdir(),
file = "testfile.fst",
keep = c(AGE, INCOME_class, State, weight),
where = age > 65)Join two or more data frames together in one operation with multiple different join methods and join on differently named variables. Available methods are: left, right, inner, full, outer, left_inner, right_inner.
# Simple join
df1 <- data.frame(key = c(1, 1, 1, 2, 2, 2),
a = c("a", "a", "a", "a", "a", "a"))
df2 <- data.frame(key = c(2, 3),
b = c("b", "b"))
left_joined <- multi_join(list(df1, df2), on = "key")
# Joining more than two data frames on different variable names with different methods
df1b <- data.frame(key1 = c(1, 1, 1, 2, 2, 2),
key2 = c("a", "a", "a", "a", "a", "a"),
a = c("a", "a", "a", "a", "a", "a"))
df2b <- data.frame(var1 = c(1, 2),
var2 = c("a", "a"),
c = c("c", "c"))
df3b <- data.frame(any = c(2, 3),
name = c("a", "a"),
b = c("b", "b"))
multiple_joined3 <- multi_join(list(df1b, df2b, df3b),
on = list(df1b = c("key1", "key2"),
df2b = c("var1", "var2"),
df3b = c("any", "name")),
how = c("left", "right"))Transpose, weight results and generate additional categories all in one operation. Put variables side by side or nest them or both, just as you need it. And of course you can transpose multiple variables from wide into long format in one go.
# Transpose from long to wide and use a multilabel to generate additional categories
long_to_wide <- my_data |>
transpose_plus(preserve = c(year, age),
pivot = c("sex + education", "sex", "education"),
values = income,
formats = list(sex = sex., age = age.),
weight = weight,
na.rm = TRUE)
# Transpose back from wide to long
wide_to_long <- long_to_wide |>
transpose_plus(preserve = c(year, age),
pivot = list(sex = c("Total", "Male", "Female"),
education = c("low", "middle", "high")))Sort cases while preserving the order of certain variables or make use of formats to sort in format order, which can be used to e.g. sort a character variable in another than alphabetical order without creating a temporary variable just for sorting.
education. <- discrete_format(
"1" = "low",
"2" = "middle",
"3" = "high")
# Simple sorting
sort_df1 <- my_data |> sort_plus(by = c(state, sex, age))
sort_df2 <- my_data |> sort_plus(by = c(state, sex, age),
order = c("ascending", "descending"))
# Character variables will normally be sorted alphabetically. With the help
# of a format this variable can be sorted in a completely different way.
sort_df3 <- my_data |> sort_plus(by = education,
formats = list(education = education.))
# Preserve the order of the character variable, otherwise it couldn't stay in
# it's current order.
sort_df4 <- sort_df3 |> sort_plus(by = age,
preserve = education)There are also some functions which enhance the readability of the code. For example if - else if - else statements like in other languages:
# Example data frame
my_data <- dummy_data(1000)
# Call function
new_df <- my_data |>
if.(age < 18, age_group = "under 18") |>
else_if.(age >= 18 & age < 65, age_group = "18 to under 65") |>
else. ( age_group = "65 and older")
# Or with multiple variables
new_df <- my_data |>
if.(age < 18, age_group = "under 18" , age_num = 1L) |>
else_if.(age >= 18 & age < 65, age_group = "18 to under 65", age_num = 2L) |>
else. ( age_group = "65 and older", age_num = 3L)
# NOTE: As in other languages the following if blocks won't produce the same result.
# if.() will overwrite existing values while else_if.() will not.
state_df <- my_data |>
if.(state == 1, state_a = "State 1") |>
else_if.(state < 11, state_a = "West") |>
else. ( state_a = "East")
state_df <- state_df |>
if.(state == 1, state_b = "State 1") |>
if.(state < 11, state_b = "West") |>
else.( state_b = "East")
# Use if.() as a do-over-loop. In this kind of loop all vectors will be
# advanced one iteration at a time in parallel.
money <- c("income", "expenses", "balance", "probability")
new_vars <- c("var1", "var2", "var3", "var4")
result <- c(1, 2, 3, 4)
do_over_df <- my_data |>
if.(money > 0, new_vars = result) |>
else.( new_vars = 0)
# All these functions can be used in a do_if() situation and are aware of
# overarching conditions.
do_if_df <- my_data |>
do_if(state < 11) |>
if.(age < 18, age_cat = 1) |>
else.( age_cat = 2) |>
else_do() |>
if.(age < 18, age_cat = 3) |>
else.( age_cat = 4) |>
end_do()The if condition functions also enable a SAS like writing style:
# Example data frame
my_data <- dummy_data(100)
# Write in intervals
my_data[["age_gr"]] <- my_data |> ifelse_multi(" age < 18 " = "under 18",
" 18 <= age < 25 " = "18 to under 25",
" 25 <= age < 50 " = "25 to under 50",
" 50 <= age < 65 " = "50 to under 65",
" 65 <= age " = "65 and more")
# With overarching do_if condition
my_data[["age_gr_edu"]] <- my_data |> ifelse_multi(do_if = " education in ('middle' 'high') ",
" age < 18 " = "under 18",
" 18 <= age < 25 " = "18 to under 25",
" 25 <= age < 50 " = "25 to under 50",
" 50 <= age < 65 " = "50 to under 65",
" 65 <= age " = "65 and more")
# And/or translation
my_data[["and"]] <- my_data |> ifelse_multi(" age > 65 and sex = 1 " = 1,
" age > 65 and sex = 2 " = 2,
else. = 0)
my_data[["or"]] <- my_data |> ifelse_multi(" age > 65 or sex = 1 " = 1,
" age > 65 or sex = 2 " = 2,
else. = 0)
# "in" translation
my_data[["in"]] <- my_data |> ifelse_multi(" age in (1 10 25 65 90) " = 1, else. = 0)
# Colon translation: start/ends with and contains
my_data[["start"]] <- my_data |> ifelse_multi(" education == 'lo:' " = 1, else. = 0)
my_data[["end"]] <- my_data |> ifelse_multi(" education == ':le' " = 1, else. = 0)
my_data[["contains"]] <- my_data |> ifelse_multi(" education == ':ig:' " = 1, else. = 0)
# Macro variables can be integrated in any place
variable <- "age"
age_to_check <- 18
value_to_set <- "under 18"
my_data[["macro"]] <- my_data |>
ifelse_multi(" &variable < &age_to_check " = "&value_to_set", else. = "other")
# NA translation
my_data[["NA"]] <- my_data |> ifelse_multi(" age == . " = 1, else. = 0)
my_data[["notNA"]] <- my_data |> ifelse_multi(" education != . " = 1, else. = 0)
# Pass in existing variable values
my_data[["income_mix"]] <- my_data |> ifelse_multi(" age < 50 " = income, else. = expenses)The functions in this package actually talk to the user and show what they are doing during runtime. The message system relies on pure base R and does not only provide built in message types, but also custom ones.
The standalone, lightweight and zero dependency version of this message system is also available with the package printify and can be downloaded via CRAN.

This package also includes some basic yet very effective performance monitoring functions. The heavier functions in this package already make use of them and can show how they work internally like this:
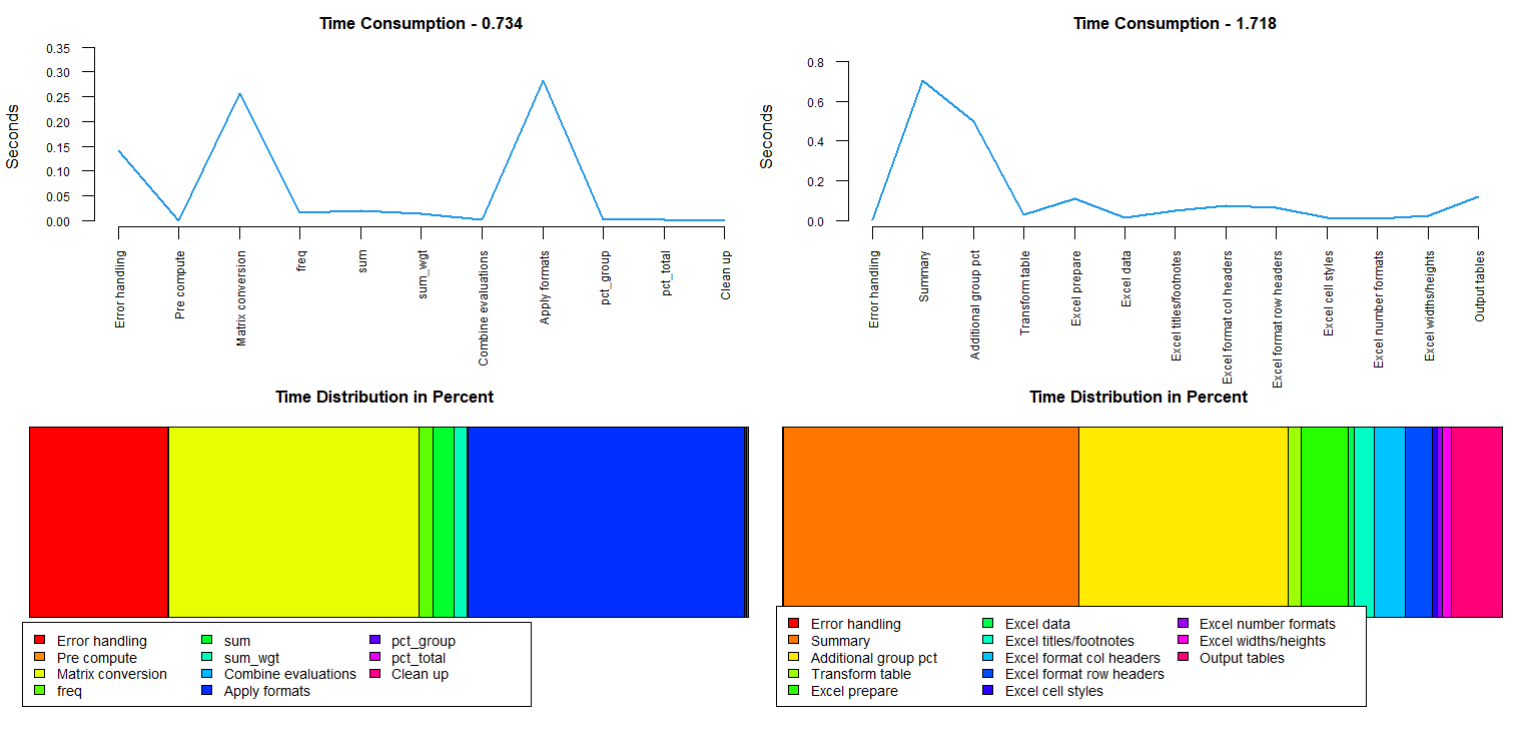
Don’t like the colors of the built-in in RStudio themes? Can’t find a theme online that fits your liking? No Problem. With a simple function you can create a full theme file and decide which parts of the editor receive which colors. The themes shown below and the corresponding code can be found on GitHub.